神经网络算法Transformer详解
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
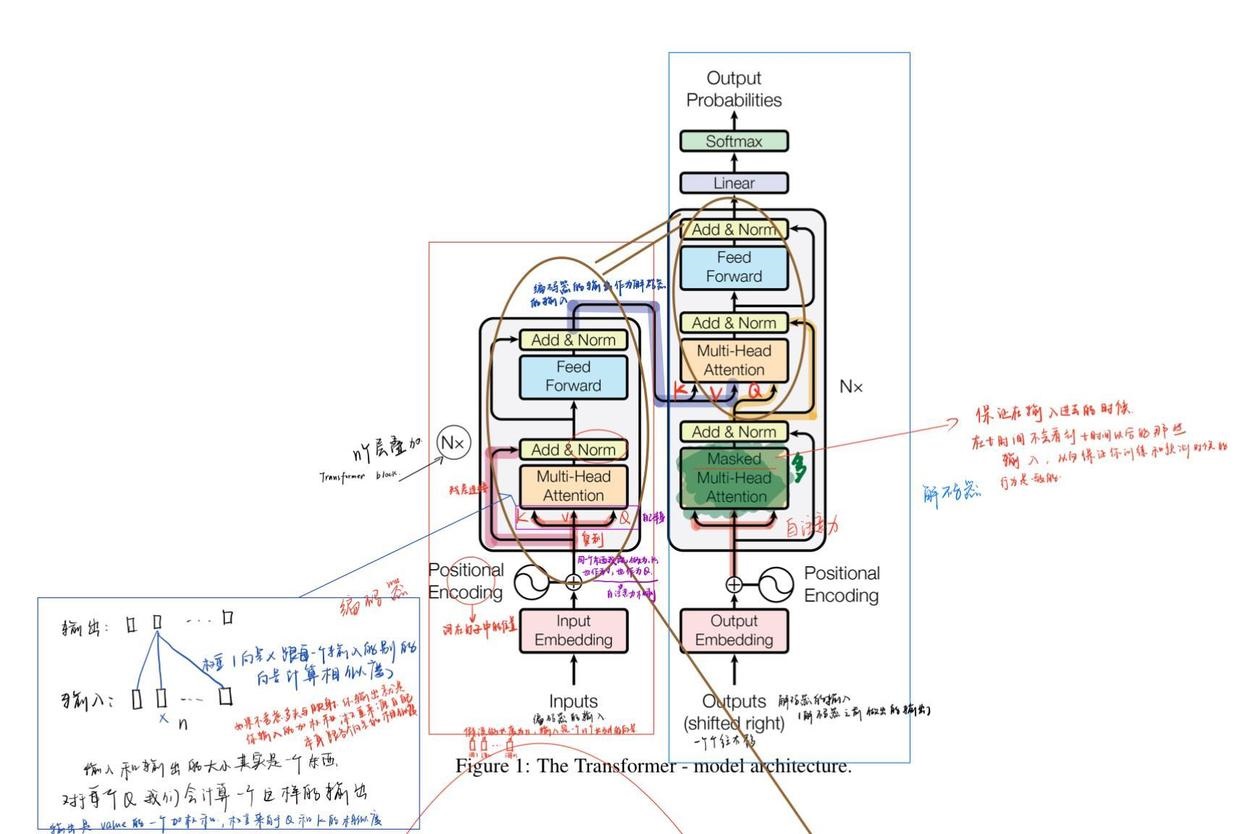 一、Transformer的基本概念和背景 1. 起源 Transformer是一种在自然语言处理(NLP)领域具有革命性意义的架构。它诞生于对传统序列处理模型(如循环神经网络RNN及其变体LSTM、GRU)局限性的突破需求。传统的RNN类模型在处理长序列数据时存在梯度消失或梯度爆炸问题,并且难以进行并行计算。 Transformer首次出现在论文《Attention is All You Need》中,它完全基于注意力机制(Attention Mechanism)构建,摒弃了传统的循环和卷积结构。 2. 核心思想 其核心在于利用自注意力机制(Self Attention)来对输入序列中的各个元素之间的关系进行建模。自注意力机制能够让模型在处理一个词(或序列中的其他元素)时,综合考虑输入序列中其他词与它的关联程度。例如,在翻译句子“我喜欢苹果”时,模型通过自注意力机制可以知道“苹果”在这个语境下是水果,而不是科技公司,这是通过考虑“喜欢”和“我”等词来判断的。 二、Transformer的结构剖析 1. 输入层 输入层首先要对原始文本进行词嵌入(Word Embedding)操作。词嵌入是将自然语言中的单词映射到一个低维向量空间中。例如,将“苹果”这个词用一个固定长度(如128维)的向量来表示。 除了词嵌入,通常还会添加位置编码(Positional Encoding)。这是因为Transformer没有像RNN那样的顺序处理结构,为了让模型知道序列中元素的位置顺序,需要将位置信息编码到输入向量中。位置编码可以是简单的正弦函数和余弦函数生成的编码方式,也可以是其他学习得到的编码方式。 2. 多头自注意力层(Multi Head Self Attention) 这是Transformer最关键的部分。 单头自注意力机制:自注意力机制的计算公式如下: 首先计算查询向量(Query)、键向量(Key)和值向量(Value)。对于输入序列中的每个元素,通过线性变换得到这三个向量。设输入序列为(X = (x_1,x_2,cdots,x_n)),通过线性变换(W_Q)、(W_K)、(W_V)得到(Q = (q_1,q_2,cdots,q_n)),(K=(k_1,k_2,cdots,k_n)),(V=(v_1,v_2,cdots,v_n)),其中(q_i = x_iW_Q),(k_i = x_iW_K),(v_i = x_iW_V)。 然后计算注意力得分(Attention Scores)(a_{ij}),它通过点积(a_{ij}=q_i^Tk_j)得到,表示第(i)个元素对第(j)个元素的关注程度。 对注意力得分进行归一化处理,通常采用Softmax函数(alpha_{ij}=frac{exp(a_{ij})}{sum_{k = 1}^nexp(a_{ik})})。 最后得到自注意力的输出(y_i=sum_{j = 1}^nalpha_{ij}v_j)。 多头自注意力机制:将单头自注意力机制复制多份(设为(h)头),对每头进行上述自注意力计算,得到(h)组不同的输出。然后将这(h)组输出进行拼接,并通过一个线性层进行降维处理,得到多头自注意力的最终输出。这样做的好处是模型可以从不同的表示子空间中学习到更丰富的特征。 3. 前馈神经网络层(Feed Forward Neural Network) 在多头自注意力层之后是前馈神经网络层。它由两层全连接层组成,中间有一个激活函数(通常是ReLU)。例如,设输入为(z),第一层全连接层的输出为(z'=text{ReLU}(zW_1 + b_1)),第二层全连接层的输出为(y = z'W_2 + b_2)。这个层的作用是对自注意力层的输出进行进一步的非线性变换,以提取更复杂的特征。 4. 残差连接和层归一化(Residual Connections and Layer Normalization) 在Transformer中,每一个多头自注意力层和前馈神经网络层之后都有残差连接。残差连接的公式为(x_{out}=x + text{SubLayer}(x)),其中(x)是输入,(text{SubLayer}(x))是子层(多头自注意力层或前馈神经网络层)的输出。这样可以避免在深层网络中出现梯度消失问题,使信息能够更好地在网络中传递。 层归一化是在残差连接之后进行的。它对每个样本的每个特征维度进行归一化处理,使网络训练更加稳定。 三、Transformer的训练和优化 1. 损失函数 在自然语言处理任务中,如机器翻译,常用的损失函数是交叉熵损失(Cross Entropy Loss)。假设在翻译任务中,目标语言有(m)个单词,对于每个单词的预测概率分布为(p=(p_1,p_2,cdots,p_m)),而真实的单词分布为(y=(y_1,y_2,cdots,y_m))(通常是one hot向量),则交叉熵损失(L=-sum_{i = 1}^m y_ilog(p_i))。通过最小化这个损失函数来训练Transformer模型。 2. 优化器 常用的优化器有Adam等。Adam优化器结合了动量法和RMSProp的优点,能够自适应地调整学习率。在训练Transformer时,通过不断迭代地更新模型参数(theta)来最小化损失函数。其更新公式为(theta_{t + 1}=theta_t-alphafrac{hat{m}_t}{sqrt{hat{v}_t}+epsilon}),其中(alpha)是学习率,(hat{m}_t)和(hat{v}_t)是对梯度的一阶矩估计和二阶矩估计的修正值,(epsilon)是一个很小的数,防止分母为零。 四、Transformer的应用和扩展 1. 在自然语言处理中的应用 机器翻译:Transformer在机器翻译领域取得了巨大的成功。例如在将中文句子翻译成英文时,它能够准确地处理句子中的语法和语义关系,生成流畅的英文译文。像谷歌翻译等在线翻译工具现在大多采用基于Transformer架构的模型。 文本生成:可以用于生成故事、诗歌、新闻等文本内容。例如,给定一个故事的开头,Transformer模型可以根据之前学习到的语言模式和语义知识继续续写故事。 问答系统:在问答系统中,Transformer能够对问题和相关的文档进行编码和理解,准确地从文档中提取出问题的答案。 2. 在其他领域的扩展应用 计算机视觉:在图像分类、目标检测等计算机视觉任务中也有应用。例如,将图像分割成一个个小块(类似于文本中的单词),然后利用Transformer的架构来处理这些小块之间的关系,能够取得很好的效果。 语音识别:可以处理语音序列,通过对语音信号进行特征提取后,像处理文本序列一样利用Transformer来进行语音内容的识别和转录。 该文章在 2025/6/18 9:05:29 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886


